Google’s suggestion feature is an interesting look into the internet hive mind. I recently noticed that the top suggestion for a search starting with “what” is “what is twitter”. Interesting, no?

I thought this might have been because of my previous searches (what you search about says a lot about you!), so I logged out and saw the same thing. Not convinced this was enough, I logged onto Google through Tor and another browser with cleared cookies. Same difference, Twitter really is getting this much curiosity from the public.
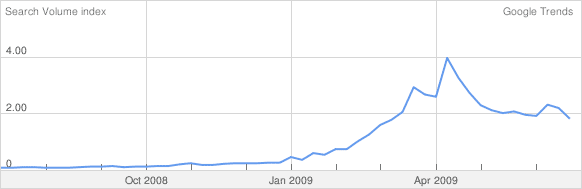
Visiting Google Trends sheds some more light on who’s looking to find out about Twitter. The search query peaked in popularity around on April 17th which coincides with the Asthon Kutcher / CNN follower race.
Richardson, TX (an affluent suburb of Dasllas) takes the prize for the city most interested in figuring out what Twitter is.
If you want to add me on twitter, I’m @jonknee.
UPDATE: I did more Google Suggestions analysis with some interesting results. Essentially we’re doomed–the most popular searches are for things no one needs to search for.
Over at It’s For Dinner I have continued to work through the basics so that future posts can have nice background and deep links. I want to do pizza for example, but before I go there I need to have marinara sauce and a versatile bread dough. Along the way I’ve done some highly topical posts about single ingredients and like the result.
Last night I put up an article about cilantro, a delicious but controversial herb. In the future when I mention cilantro I just have to link back–I already covered what it is, how to store it, why you should ask dinner guests before using it, etc. Another recent example is olive oil.
It can be tedious at times, but I’m learning stuff and I think laying the foundation will pay off.
Boston.com’s Big Picture started the trend, but there have been some recent upstarts in the world of high-resolution news photo blogs. I love these types of sites, the world is more interesting in HD. Print media is dying, but journalism is more than words on paper.
Anyone know of any more?
 Kanes Furniture runs a promotion in partnership with the Tampa Bay Rays and Papa Johns than entails giving out coupons for a free 10″ pizza when the Rays get 10 or more strike outs (K’s) in a home game. It’s a fun promotion and a nice bonus when the Rays get more than 10 strike outs, which has happened a couple of times already this year. It’s promoted frequently during the local television broadcasts of the games and there is a strikeout tracker in the stadium made out of Kanes’ styled K logos.
Kanes Furniture runs a promotion in partnership with the Tampa Bay Rays and Papa Johns than entails giving out coupons for a free 10″ pizza when the Rays get 10 or more strike outs (K’s) in a home game. It’s a fun promotion and a nice bonus when the Rays get more than 10 strike outs, which has happened a couple of times already this year. It’s promoted frequently during the local television broadcasts of the games and there is a strikeout tracker in the stadium made out of Kanes’ styled K logos.
To register for your coupon you either fill out a form online or show up at Kanes with your ticket stub. The online option is great, but features a massive security hole. After filling out the form you get thrown to the print page, which in normal use goes away automatically after you deal with the print dialog box thanks to JavaScript. But the site isn’t entirely Mac friendly and I started poking around and discovered that the URLs of the coupons look like:
http://www.kanesstrikeoutcontest.com/contest/coupon/index.php?cID=X
Where X equals an integer. A fairly small integer. Small enough to appear to be an auto incrementing ID… Could it really be that simple? Yes, you really can view everyone’s coupon which happens to feature their address, email address and phone number. Even better, this information is provided in plain text–trivial to screen scrape. The IDs start at 6 and go up to over 22,000–there are a lot of people affected.
I talked to Wayne Liburd, the Director of MIS at Kanes, about this issue last week and he immediately realized they had a problem and asked what I would charge to fix it. A followup email from Wayne noted that he’d rather not pay more than a few pizzas worth of money to fix the problem. You get what you pay for and it’s not surprising that his website is giving away his customers’ privacy. I followed up to offer an exchange for Rays tickets (assuming that as a large sponsor they have access to such things) and he declined to reply.
I gave him the game plan for free–email the coupons or use a non-incremental ID like UUID. I hope he takes the advice.
Jon,
Good morning, I would not be willing to pay any more than $50/hr for an independent consultant to work on my website.
Thanks,
Wayne Liburd
Director of MIS
Update on June 10th 2009: Wayne dropped me a note today stating that the issue has been fixed along with a request to delete this post. It does appear that the issue I pointed out has been fixed, but I won’t be able to tell if it was a legitimate fix until the next time the Rays get more than ten strike outs (hopefully soon!). Wayne assures me it was a real fix, so I’ll take him at his word. As for deleting the post? Not a chance.
Update on June 17th 2009: As luck would have it, the Rays got 10 strike outs the night after my previous update and the verdict is in: Kanes Strikeout is still insecure. I sent Wayne Liburd a copy of someone else’s coupon the night of the game (June 11th) and have not yet heard back. Instead of taking my advice to use non-sequential IDs or emailing the coupons, Wayne apprently had the site updated to only allow a coupon to be viewed once. A curious call on his part as non-sequential IDs is no more difficult to do and would be several orders of magnitude more secure.
Second Street Media Solutions has a service called upickem that runs voting sites for various groups, including one for the tbt*. A friend is in one of these contests so I have voted a few times (you can log a vote once per day). Strangely enough after a couple of rounds I have had autofill help out on the CAPTCHA and even more strangely it was right. I checked the source and found the problem: they simply use one of 30 sequentially named JPEG files to make what appears to be but really isn’t a CAPTCHA. This reeks of management saying, “do that thing where you type in what you see” and development faking it. Unsurprisingly, the use of custom subdomains was lazily implemented too–any other [sequential] ID can be subbed in and you can see other ongoing contests inside the wrong template.
The sad part is they charge money for this stuff. Well that’s not sad, the sad part is people actually pay for it.

I had a pleasant time yesterday hooking Zendesk into an existing Django site (using django.contrib.auth). Their API has a hook for remote authentication which is a lot easier than their chart makes it look. Actually it was accomplished in only a couple lines of Python.
You need to tell Zendesk two URLs, one for where it sends users to log-in and then another for where to send them when they log-out. For me that meant creating one new view (to send the login details to Zendesk). Here’s about what it looks like:
@login_required
def authorize(request):
try:
timestamp = request.GET['timestamp']
except KeyError:
raise Http404
u = request.user
hash = md5.new('%s %+s%s%s%s' % (u.first_name, u.last_name, u.email, settings.ZENDESK_TOKEN, timestamp)).hexdigest()
url = "%s/access/remote/?name=%s %s&email=%s×tamp=%s&hash=%s" % (settings.ZENDESK_URL, u.first_name, u.last_name, u.email, timestamp, hash)
return HttpResponseRedirect(url)
That’s it. We’re hooked in. It requires two custom settings (ZENDESK_TOKEN and ZENDESK_URL) which you get from Zendesk, but otherwise should work in your Django app. When the user clicks “login” from Zendesk, they get directed to this view with a GET variable called timestamp. The view makes sure the user is authenticated (if not it shows the login page and gets the user to login) and then creates a hash to send over to Zendesk. To the user it’s all transparent. Kudos to Zendesk on making it so easy.
Update: I have made this into its own pluggable Django app called django_zendesk and posted it up on BitBucket.

I have been cooking/baking up a storm lately and recently started to document it over at It’s For Dinner. It’s a work in progress, but I’m having fun. The site’s powered by a custom Django project which is also a work in progress and a fun time. The search/archive features are quite basic at the moment, but that will be expanded once there is actually content to fill them up. I have a lot of upcoming recipes to feature, but for now consider it a sneak preview.
I have been trying to feature building blocks early on as future recipes will link back to the parts. For example last night I made steak sandwiches, but that’s really three recipes in one: dinner rolls, caramelized onions and a perfect steak. Assemble along with a crisp pickle and perhaps some dijon and you have a sandwich.
Speaking of last night, I also made these Ritz crack cookies which are unbelievably good. I know I know, it sounds like something Rachael Ray or Sandra Lee would do, but go ahead and try. Epic.
Update: I did a fairly decent update of the CMS last night and added in tagging and popularity tracking. The archive page is really starting to come together. I love how the whole site is really plain–nothing more than a tumblelog. Big beautiful photos help and I’m getting better at that, shooting food is tough. Especially when hungry.
This is mostly a reminder for my future self, but maybe it will help someone else. Given a database table that contains columns for latitude and longitude (in decimal notation), here’s how to pull rows nearest to a point. For more complex operations it makes sense to use a database with geospatial features (perhaps PostegreSQL with PostGIS), but this is simple and will work fine with something like MySQL.
Let’s call our table “locations”, the latitude column “latitude” and the longitude column “longitude”. We’re checking for locations near the point [27.950898, -82.461517] and we want the nearest five locations. Here’s the SQL:
SELECT *,
SQRT(POW((69.1 * (locations.latitude - 27.950898)) , 2 ) +
POW((53 * (locations.longitude - -82.461517)), 2)) AS distance
FROM locations
ORDER BY distance ASC
LIMIT 5
The distance column in your results is formatted in miles and is reasonably accurate but nothing to bet your life on.
Read more
I recently delved into the world of desktop programming by learning Objective-C / Cocoa. My guide was the excellent Cocoa Programming for Mac OS X 3rd edition which was written by Aaron Hillegass of Big Nerd Ranch fame. I haven’t read a computer book cover-to-cover in a while which is a testament to the quality of Aaron’s book. One thing to know going in is that he doesn’t spend much time teaching Objective-C as it’s not a large language, especially if you know C. The book is mostly centered around the APIs you’ll be using to make applications. Apple has a good Objective-C primer that will get you up to speed on the language front. I wouldn’t recommend Objective-C/Cocoa as a first programming environment, but it’s easy enough to follow if you know some others.
I completed all the exercises in Cocoa Programming for Mac OS X, but there’s a difference between being book smart and actually writing applications. I decided to scratch an itch I’ve had for months and write a screensaver that displays meta data about the JPGs its displaying. Specifically the IPTC “Caption/Abstract” field which is utilized religiously by a feed of high-quality AP photos I subscribe to. The built in photo screensaver simply displays them, but I often want to know what the photo is of and it’s a pain to stop the screen saver, go to the directory, hunt through 200 images just to find the one I want the caption for.
 It’s is a really simple app which is perfect for a first time project. In fact it’s all a single subclass of ScreenSaverView. My first challenge was how to pull the meta information and I ended up going with the ImageIO framework. Then I needed to know how to draw it on the screen, that’s simple enough with
It’s is a really simple app which is perfect for a first time project. In fact it’s all a single subclass of ScreenSaverView. My first challenge was how to pull the meta information and I ended up going with the ImageIO framework. Then I needed to know how to draw it on the screen, that’s simple enough with drawInRect:withAttributes:, but calculating the rectangle proved a little tricky since it should be as wide as the screen and variably tall based on the amount of text. It’s still not perfect, but using sizeWithAttributes: let’s me know how much area it will take. It would be really handy to have a height:WithWidth:WithAttributes: method.
My images are all quite large (typically larger than 6 megapixels) so they have to be scaled correctly for display. I hit a wall here because the images were originally coming up much smaller than I knew they were, the reason was resolution (thanks!).
Then I hooked up ScreenSaverDefaults and configureSheet to allow users to choose a source folder and speed. Nothing special here. I’ll probably add an option for random display at some point.
The resulting app is exactly what I wanted. It looks spectacular on both my 24″ display and 50″ TV (hooked into a Mini running a separate instance of the feed and screensaver). I often have the AP photos on when people come over because it’s such a great conversation starter, now with having the captions available we might learn a thing or two. Sadly this could be a competitive cable news station–it’s already more informative than CNN/Fox.
Mission accomplished.
Being that I work almost exclusively online, I can go a long time using but not actually talking about a technology. Then one day I’ll hear someone mention it and realize that I had been mispronouncing it in my head all this while. Today’s lesson was Memcached. As in mem-cache-dee. That makes so much sense (it’s a daemon after all), but I had gone ahead thinking it was pronounced as it looks (mem-cached). Both make sense and without a space or capitalization I feel my guess was appropriate if not naive. Luckily I wasn’t the first to speak about Memcached at this meeting, so I kept up the illusion of competence and locked up my learning something every day goal.
While it didn’t happen today (score one for not speaking first), mis-pronouncing a technology in front of peers produces an awkward situation for both parties. I have been on each side and I can’t say which is better other than ignorance is bliss. If you’re on the receiving end there’s always a chance that you are actually the incorrect one and correcting the speaker would be a major gaffe. Even if it’s a sure bet, correcting someone is a sensitive situation. If it’s your superior and there are others around, correcting is almost always out of the question and you’re left with the dreadful decision of either using the [possibly] incorrect pronunciation in the rest of the meeting or using the [presumed] correct pronunciation at the risk of alienating your superior.
Have this happen at a meeting with clients and you’re in it even deeper–maybe they are testing you and want to know you really know your stuff. Maybe they really don’t know. Maybe I’m over thinking it? Let’s hope.
The last time I remember having to punt was when someone said “app-pee” and I was completely lost. A few minutes of confusion later I realized we were talking about an API. I was aware of Sequel/S-Q-L, but app-pee was new and uncomfortable territory.

{kind=link}
{kind=link}
{kind=link}
{kind=link}